发表自话题:2020无视征信大数据秒下5万
一大长串的概念,看的人云里雾里,想要理解大数据,我还是不建议看这些定义的,直接看帆软君给大家准备的例子就可以了!
前几天看了这么一个故事:茑屋书店。
啥?一个破书店,怎么就和大数据产生关系了?
它做了2件事情:
1、类似于啤酒和尿布的故事,什么书旁边就摆放什么东西,在美食书旁摆放优雅的餐具,在科幻电影DVD旁放上推理小说。

2、会员卡营销
每个人都有一张会员卡,而且这卡在指定的门店都是通用的,当用户消费之后,就可以通过数据来看用户到底偏好什么,就比如淘宝那样,分了300多个维度来做消费者画像来导出消费偏好并进行标记,推送给其他行业的伙伴,开始做数据营销。
你在零食店买了A,但是店员通过你的消费记录发现你也喜欢B,那就会给你推荐。
大数据,不仅仅是数据量大,数据范围广,数据维度多,这些都是表层意义,真正能用起来的数据才叫大数据。
举几个帆软君做的关于大数据的事情吧。
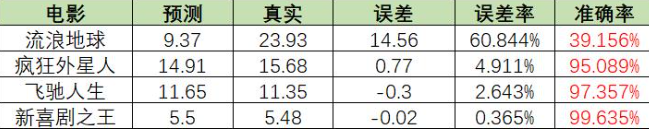
19年的时候,春节档关注的电影一共有《疯狂外星人》、《流浪地球》、《飞驰人生》、《新喜剧之王》四部,而关于这几部电影的票房,我们的团队在电影上映一周前就做了出了预测:
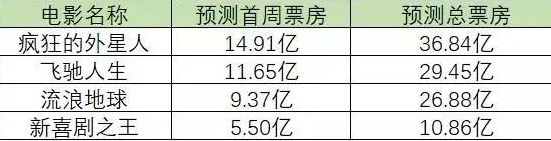
截止到2月12日早上9点,我们再来看一下首周票房对比结果:

除了《流浪地球》这匹黑马杀出重围之外(挖掘算法也没想到国产科幻电影也有翻身的一天),其他电影的预测结果与实际结果几乎完全吻合!
那么,我们是怎么用数据挖掘预测电影票房的呢?简而言之思路就是先根据历史票房变化预测出春节档总票房,然后根据各导演、演员制作的历史电影质量、票房情况、SEO情况等预测出各电影票房占比,之后综合预测出各电影的实际票房。
1、获取数据
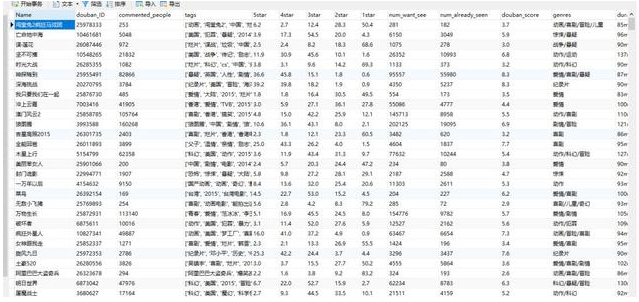
从m1095、票房网、豆瓣网等获取电影票房、质量、属性等数据,如下图:
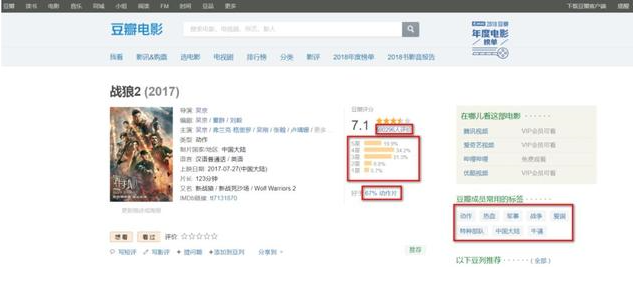
获取数据如下:
影响电影票房的三个重要因素:电影质量、电影宣传力度、档期电影总票房。
2、用算法工具进行预测
预测出2019年春节档首周总票房为76亿,预测步骤如下图:
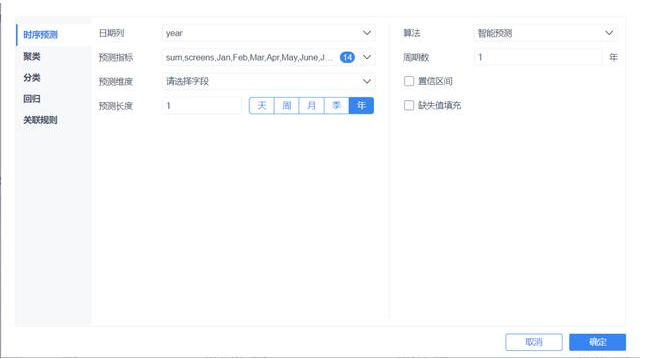
之前的这个工具是FineBI,但是现在因为一些原因,我们已经把FineBI里的数据挖掘功能给pass了,不过不影响它的使用,这只是其功能里非常非常非常小的一部分。
3、预测电影质量,从而预测电影在该档期的票房占比
如何使用历史数据来预测电影质量?对于电影来讲不变的就是那些导演与演员,导演的水平与演员的水平基本决定电影质量从而影响电影票房。
为了客观衡量导演、演员水平,根据历史电影评分、导演信息、演员信息、票房信息、电影类型信息、评价信息等特征进行组合最终共有74个特征,再结合历史票房数据等通过加权算法分析得到四部电影的票房占比情况,处理后的数据如下:

4、结合SEO、市场响应等优化票房占比
电影票房还与SEO等相关,我们找寻了百度指数、指数、淘票票指数等数据,如下图:

从历史数据发现这些指数与电影票房呈正相关关系,也就是指数越高票房越高,加入这些指数后, 使用算法重新进行预测得到我们最后的票房预测结果如下:
衣架服饰是一家大型的品牌服装企业,每年都会在全国开设许多门店,那这店铺的选址怎么做呢?
一般的做法是组建一个选址团队,到现场进行实地考察,然后根据粗略统计的统计,预测一下这个地方的销售量会怎么样,然后对比分析之后靠经验选择一个地址。但这种方法成本大,效率低,误差大,而且非常仰仗经验。
为了解决这个问题,衣架服饰希望能够用更科学的方法优化店铺选址,于是就用到了数据挖掘:
1、数据处理:
衣架原有的数据包括店铺基础数据以及旧店铺的历史销售数据,项目团队首先对这些已有的数据进行格式化统一,然后收集了原始数据没有的人流量、消费水平、消费时尚等数据,将获取的数据根据业务与后续算法实施来进行预处理,比如异常值删除、缺失值填补、数据标准化等处理。
如下图,是使用lof算法进行异常值筛选的过程:

2、特征工程与模型构建
所谓特征工程就是与预测结果相关的特征(指标)组合,也就是与新店铺相关的销售额特征组合。
该项目的原始数据加上结合业务知识生成的组合特征与leakage特征,构建的特征工程共计80余个,通过CFS、MRMR、MBF等方法综合分析,去除相关性权重不高的特征,最终剩余40余个。
然后建立算法模型,适合该项目的算法有决策树、随机森林、回归、XGBOST等。最后通过模型准确率以及模型与业务的契合度对比,选择了随机森林作为模型算法。
3、模型优化
模型优化主要是在找到模型可改进的地方之后所做的事情,比如模型算法的参数调整、特征工程调整等。该项目中模型优化过程除了参数调整,主要就是依据业务,进行特征工程的调整以及数据清洗。比如业务研究过程中发现新的相关特征,需要将其加入特征工程。
4、得出结果
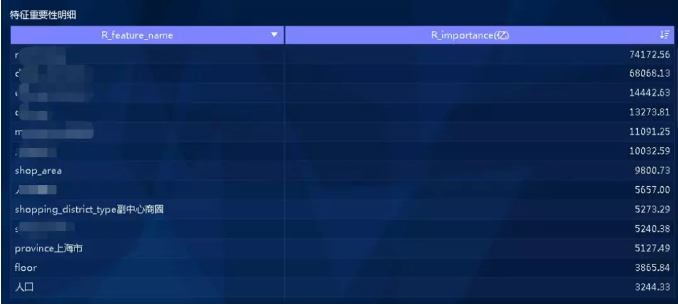
在该项目中,将特征与销售额的相关性用权重来表示,权重越高表示该特征与销售额的相关性越强,权重结果如下:
利用建立的模型预测出某个新店铺一年的销售额,预测如下:

5、误差分析
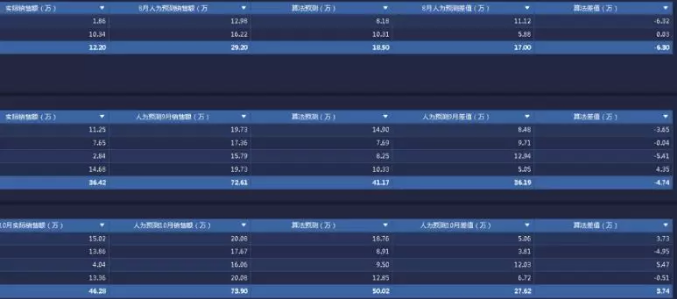
预测的结果究竟准确不准确呢?团队将新店铺销售额拿来与人为预测销售额、实际销售额做了个误差分析,以此来衡量店铺销量预测误差。如下图所示,人为预测月平均误差为8.08万,算法预测月平均误差为1.478万,人为预测误差大概为算法预测误差6倍。算法预测最小误差仅300元,预测精度最高为99.7%!
其实关于大数据案例,实在是太多了,我们在做报表& BI(商业智能)应用,并且这项事业已经开展了10余年。
具体做什么呢?
帮企业规范化报表业务,建立数据分析中心,搭建自助的业务分析平台,简单点说就是提供企业的数据化管理服务。并且,这项事业可应用于每个行业,目前已收获15000+客户。
先后研发了两款数据产品,一款是FineReport,另一款是FineBI。前者解决报表的制作和管理问题,后者解决业务的快速分析。
帆软:你用过Excel,却不知还有一款神器“FineReport”zhuanlan.zhihu.com 帆软:大屏做成这样,领导不重用你都难!zhuanlan.zhihu.com
帆软:大屏做成这样,领导不重用你都难!zhuanlan.zhihu.com 帆软:Excel,python全都靠边站,这才是数据分析应该有的样子zhuanlan.zhihu.com
帆软:Excel,python全都靠边站,这才是数据分析应该有的样子zhuanlan.zhihu.com
我们也会在大数据的路上,一直走下去~

2021-08-31

一位短线天才坚决的MACD+换手率选股战法,简单实用,通俗易懂
2021-08-31

2021-08-23

2021-08-12

2021-08-16

2021-08-01

2021-07-27

2021-02-27

2020-10-10

2020-09-09

