发表自话题:审核简单的网贷
写在前面:本人从事车贷行业审核,从一开始的车贷风控审核,到个别产品的评分卡,都有接触,商科毕业,数学功底不扎实,但是对于审批系统背后的逻辑却有着莫名的好奇心。包括对审批模型,审批规则的建立,和建模数据的筛选等都有一系列的自学和培训。奈何终不得其精髓,闲来得空,知乎上得一业务分析的文章,分析语言是R。虽然机器学习时候使用的是Python,但是好在计算机语言都有一定的相通性,遂仔细观摩后将其翻译成Python代码,并写文章发表于知乎,以资自励!!
PS:的R语言代码以及文章,文末奉上链接。
废话不多说,下面开始:
本文数据kaggle上的Prosper网贷平台2005~2014十年间的数据,在此通过对业务数据的筛选和特征的选择,对十年间业务数据的“交易金额”、“投资者分布状况”、“每月交易笔数变化”、“增长率”等等指标做了一些指标分析,并画图展示之。
此次分析用到的第三方模块主要是numpy,pandas,datetime,以及画图模块seaborn,matplotlib。由于pandas目前在处理大数据上的优势(相比较R语言的一些统计指标仍有欠缺)故在数据处理方面只使用pandas足够。
1,引入模块并导入数据:
# 引入模块 import pandas as pd import numpy as np from pandas import DataFrame, Series import matplotlib.pyplot as plt from datetime import datetime import seaborn as sns %matplotlib inline # 导入数据 df = pd.read_csv('prosperLoanData.csv', sep=',') df.head() # 查看前5行数据 共81个特征,由于只对某一些特征做分析,故下面会选择所需子集进行分析。
共81个特征,由于只对某一些特征做分析,故下面会选择所需子集进行分析。数据结构如下图:
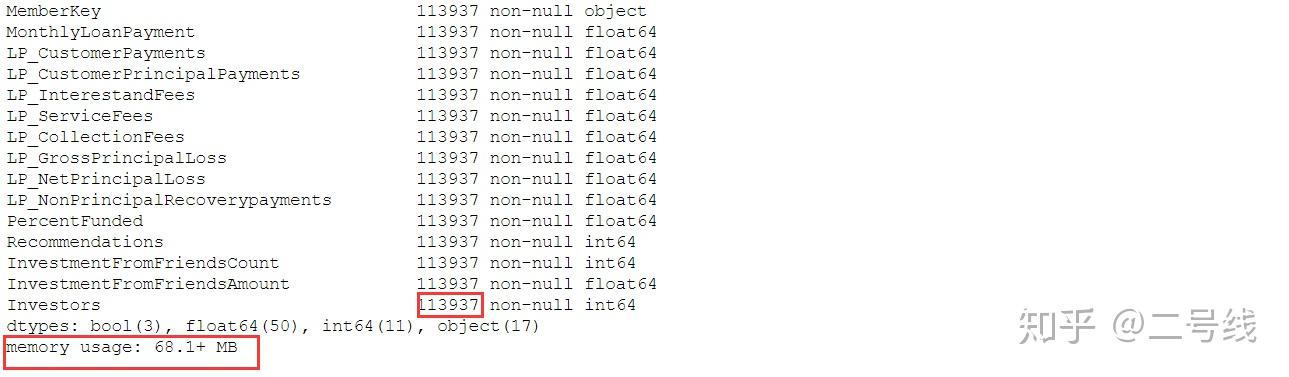 可以看出数据量还是比较大的,占用内存68M,共个实例,通过观察可发现只有少量NA数值,且绝大部分为float64类型和object类型。
可以看出数据量还是比较大的,占用内存68M,共个实例,通过观察可发现只有少量NA数值,且绝大部分为float64类型和object类型。其中一些变量的解释如下:
ListingCreationDate: 表创建时间(可能是交易开始计息时间)
LoanStatus: 贷款状态(Completed、Current、Defaulted、Chargedoff等)
EmploymentStatus: 受雇佣状态(Self-employed、Employed等)
EmploymentStatusDuration:受雇佣状态持续时间(以月为计算单位)
IsBorrowerHomeowner:借款人是否拥有房屋
CreditScoreRangeLower/CreditScoreRangeUpper:消费信用最低/最高分
InquiriesLast6Months:最近6个月查过多少次征信记录
BorrowerRate:借款标利率,作为P2P平台资金借贷价格的代理变量,BorrowerRate不包含其他费用,是筹资者付给投资人的报酬,也是融资最直接和最重要的成本,其体现了资金供求双方在综合考虑各种因素情况下所认可的资金使用成本.
Term:期限,筹资者通过网贷平台进行借款时所承诺的最终偿还期限,借款期限体现该资产的流动性,期限较长的资产应存在着流动性溢价(利率上涨).
CreditGrade/ProsperRating(Alpha):信用等级,前者反映的是2009年7月1日前客户的信用等级,后者反映的是2009年7月1日后的信用等级.信用等级越高,其偿债能力越强.
CreditScore:由消费信用公司提供的消费信用评分,类似于国内的芝麻信用分。
StatedMonthlyIncome:客户月收入,月收入越高,投资者对该借款本息按时回流越有信心.
DelinquenciesLast7Years:信用资料提交时借款人过去7年违约次数,该指标在一定程度上可以体现借款标的发布者的信用状况
BankCarduse:信用资料提交时借款人信用卡使用额度和信用卡总透支额度的百分比,本文将这个数据分成四组(mild use;medium use;heavy use;super use)
LoanOriginalAmount:借款人在借款时已经向prosper借入的资金,如果没有历史记录则为0,显然,借入本金越多,其还款压力越大,但是这项指标大的话也可能该客户对prosper依赖性较强.
DebtToIncomeRatio:借款人的债务收入比,债务收入比越高筹资者财务状况越差,还款能力较低.其向P2P平台借款时,投资者应要求有更高的回报.
Occupation:贷款人职业
IncomeRange:贷款人年收入范围
BorrowerState:贷款人所在州
Customer_clarify:0或NA是未在prosper贷过款的客户,反之是贷过款的。
2,处理空值和NA值,选择子集,并做时间日期的转换,便于后期分组处理:
loansubtime = df[pd.notna(df.ListingCreationDate)]# 去掉NA值 # 选择一个子集进行分析 loansubtime = loansubtime.loc[:,['MemberKey', 'LoanKey', 'LoanOriginalAmount', 'ListingCreationDate', 'BorrowerAPR', 'BorrowerRate', 'BorrowerState', 'Occupation', 'EmploymentStatus', 'EmploymentStatusDuration', 'IsBorrowerHomeowner', 'CurrentlyInGroup', 'GroupKey', 'DateCreditPulled', 'CreditScoreRangeLower', 'CreditScoreRangeUpper', 'TotalCreditLinespast7years', 'DebtToIncomeRatio', 'IncomeRange', 'StatedMonthlyIncome', 'TradesNeverDelinquent (percentage)', 'MonthlyLoanPayment', 'Investors']] loansubtime.head() 可以看出共选择了23个特征子集,且交易计息时间ListingCreationDate格式不规则,需要做处理:
可以看出共选择了23个特征子集,且交易计息时间ListingCreationDate格式不规则,需要做处理: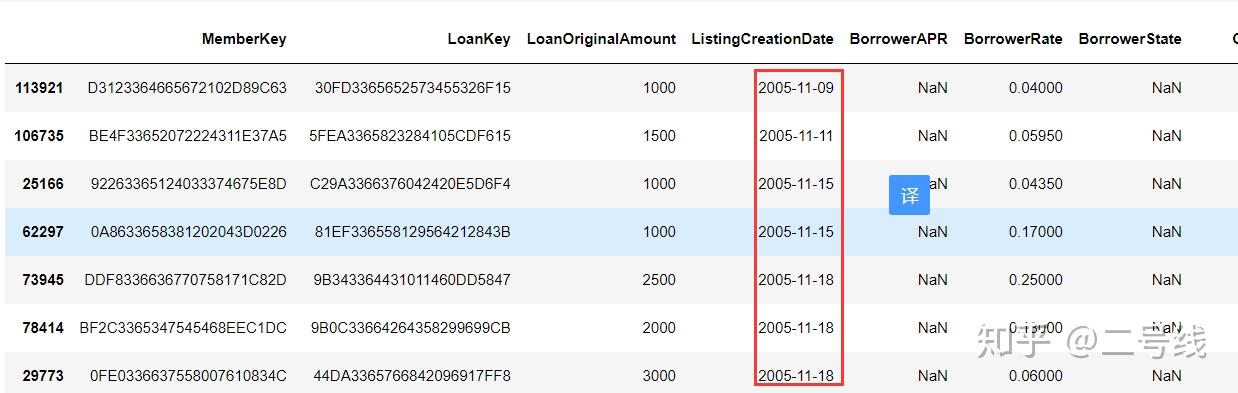 按照时间排序
按照时间排序3,以上数据基本满足下面分析的需求,开始下一步:
totaltrade = len(loansubtime.ListingCreationDate) totaltrade startTime = loansubtime.ListingCreationDate[] endTime = loansubtime.ListingCreationDate[64766] days = endTime - startTime day = days.days #days是一个timedelta属性的数值,可以用.days来提取其天数的值 month = day//30 monthTrade = totaltrade/month totalAmount = loansubtime.LoanOriginalAmount.sum() monthAmount = totalAmount/month perAmount = totalAmount/totaltrade交易笔数:
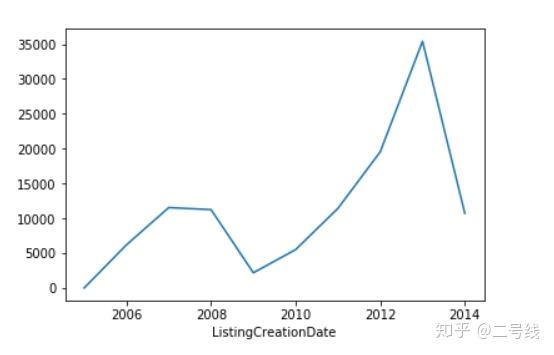 将数据按年分组,并画图查看每年交易量趋势图。可以看出从2009年到2013年呈指数倍增长,表明业务量增长可观,公司业绩逐年递增,业绩喜人
将数据按年分组,并画图查看每年交易量趋势图。可以看出从2009年到2013年呈指数倍增长,表明业务量增长可观,公司业绩逐年递增,业绩喜人将日期精确到“年-月”的格式,并计算每月交易金额,画出趋势图:
loansubtime['date'] = [datetime.strftime(x, '%Y-%m') for x in loansubtime['ListingCreationDate']] group = loansubtime.groupby('date') monthTradeAmount = group['LoanOriginalAmount'].apply(sum) monthTradeAmount = pd.DataFrame(monthTradeAmount) monthTradeAmount.columns = ['actualmoney'] monthTradeAmount['TimeNum'] = range(1, len(monthTradeAmount.actualmoney)+1) plt.figure(figsize=(12,6)) x = monthTradeAmount.TimeNum y = monthTradeAmount.actualmoney plt.plot(x, y, 'b--') plt.title('Prosper TradeAmount per month') plt.xlabel('Time(year-month)') plt.ylabel('Trade Amount') plt.show() 从图中也可以很明确的看出,业务量到达2013年时候是一个顶峰,且逐年递增,业绩喜人,但是2013年以后开始断崖式下跌,这可能和公司策略或者国家政策有直接关系
从图中也可以很明确的看出,业务量到达2013年时候是一个顶峰,且逐年递增,业绩喜人,但是2013年以后开始断崖式下跌,这可能和公司策略或者国家政策有直接关系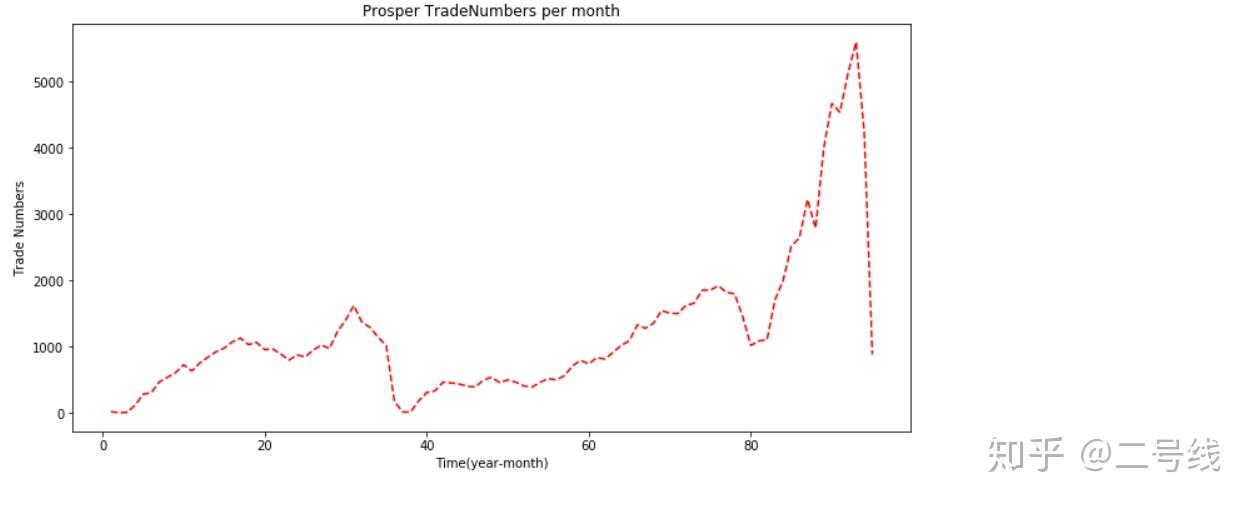 可以看出每月交易笔数也是同样的情况,交易笔数和交易金额成正比
可以看出每月交易笔数也是同样的情况,交易笔数和交易金额成正比4,下面看一下投资者数量的情况:
(1),首先看一下每笔交易笔数有多少个投资者。
 投资者列的描述信息
投资者列的描述信息选择于投资者有关的字段并建立一个子集,将投资者大于1的重新赋值为“2~1189”,并做分类处理
 投资者有关字段的子集(前5行数据)
投资者有关字段的子集(前5行数据)画图展示投资者分布情况:
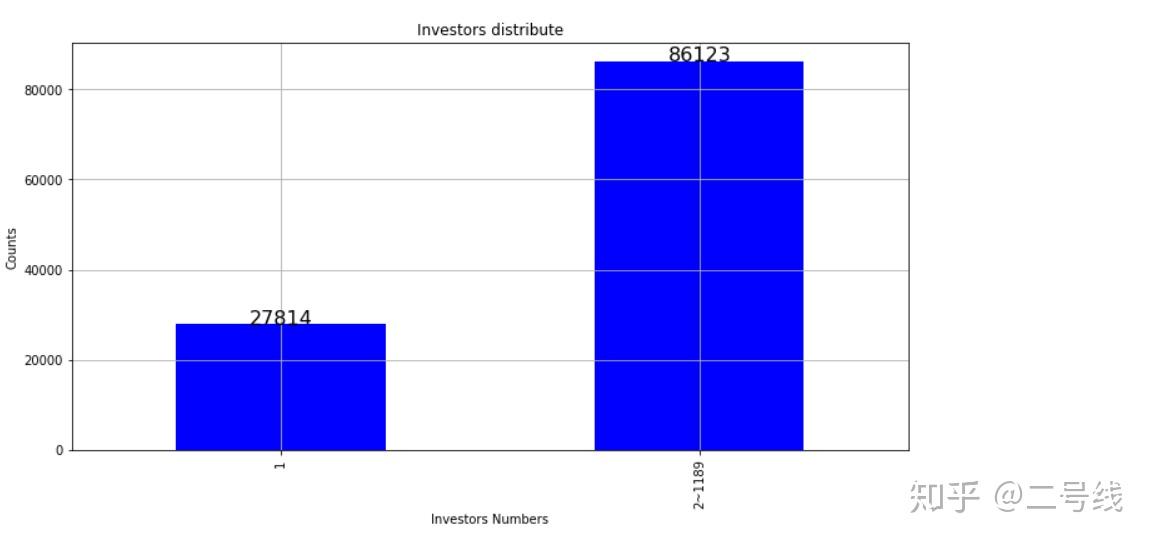 可以看出分布在2个以上投资者的贷款笔数远远大于投资者在1个的贷款笔数
可以看出分布在2个以上投资者的贷款笔数远远大于投资者在1个的贷款笔数(2),交易金额的分布情况:
 查看交易金额的数据描述信息
查看交易金额的数据描述信息将数据分组,并画出图形展示
# 利用cut函数将不同交易金额进行分类,并画图 bins = np.array([900,6500,10000,25000,36000]) a = pd.cut(loansubtime.LoanOriginalAmount, bins) b = DataFrame(a) c = b.groupby('LoanOriginalAmount').size() c.plot(kind='bar', figsize=(12,6), color='blue') for x,y in enumerate(c): plt.text(x, y+100, '%s'%y, ha='center', fontsize=16) plt.title('LoanOriginalAmount Distribute') plt.xlabel('LoanOriginalAmount') plt.ylabel('Counts') plt.grid(True) plt.show()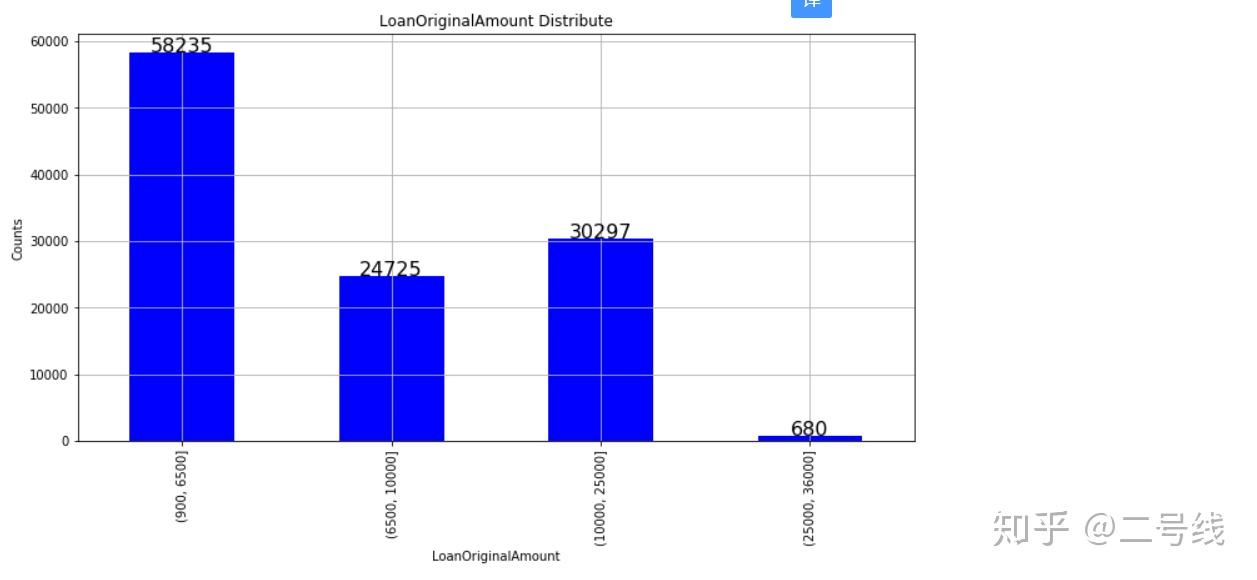 可以看出不同交易金额的数量分布情况,其中900~6500的交易金额占一半以上的数量,当然也可以选择不同的分组情况来查看
可以看出不同交易金额的数量分布情况,其中900~6500的交易金额占一半以上的数量,当然也可以选择不同的分组情况来查看(3),当前交易状态的分布情况:
# 对交易状态为cancelled的不做分析 loan_status = loan_status[~loan_status.LoanStatus.str.contains('Cancelled')]按照loanstatus状态分组可得到
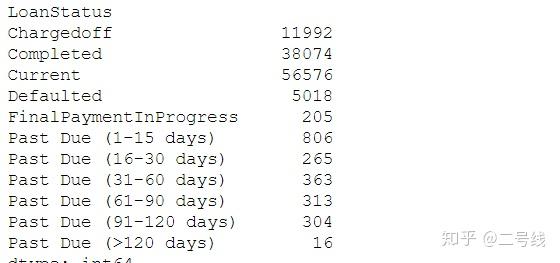
画图展示:
 可以看出completed和current状态的贷款笔数占到绝大多数,当前平台的借款情况比较健康,没有出现大规模违约的现象
可以看出completed和current状态的贷款笔数占到绝大多数,当前平台的借款情况比较健康,没有出现大规模违约的现象5,构造坏账损失金额表,并做分析(由于平台在2009年7月以后做出过大规模调整,模型和利率分布均有调整,故将其分开来查看)
通过特征'ProsperRating (Alpha)'(2009.7以后)和'CreditGrade'(2009.7以后)来将数据分为两段,构造资金损失数据表
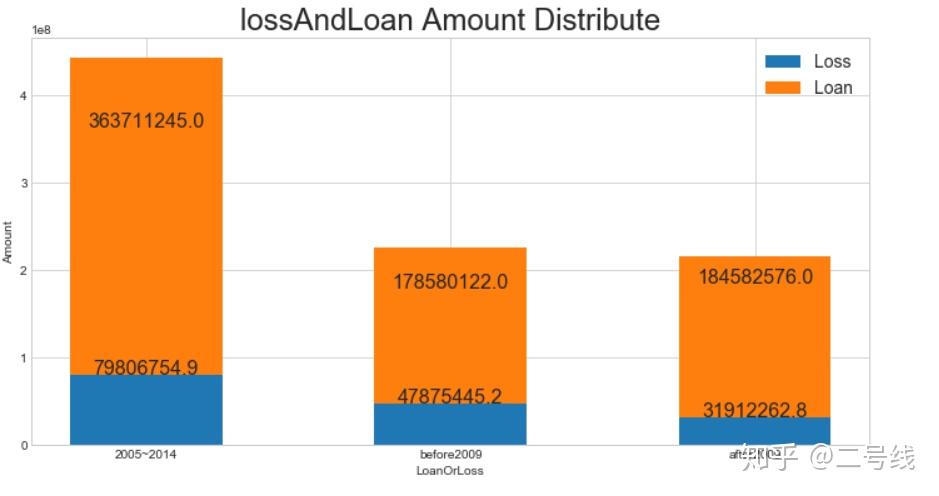 可以看出在2009年以后,通过模型调整,平台借款的违约量下降很多
可以看出在2009年以后,通过模型调整,平台借款的违约量下降很多 分开展示
分开展示6,每月交易金额的增长情况
在pandas中可以通过pct_change()函数来计算每月的教育增长率
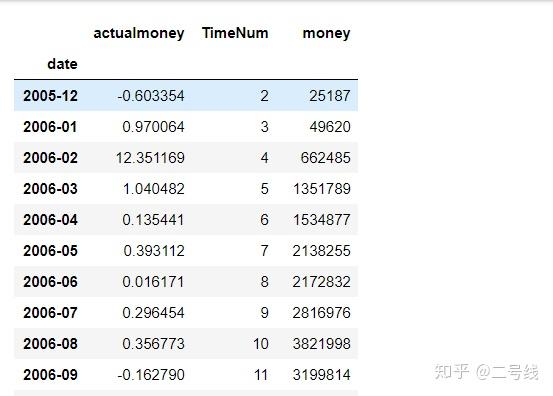 actualmoney是增长率,由于第一个月数据无意义,故删去,从2005.12开始算起
actualmoney是增长率,由于第一个月数据无意义,故删去,从2005.12开始算起画图展示增长率的情况
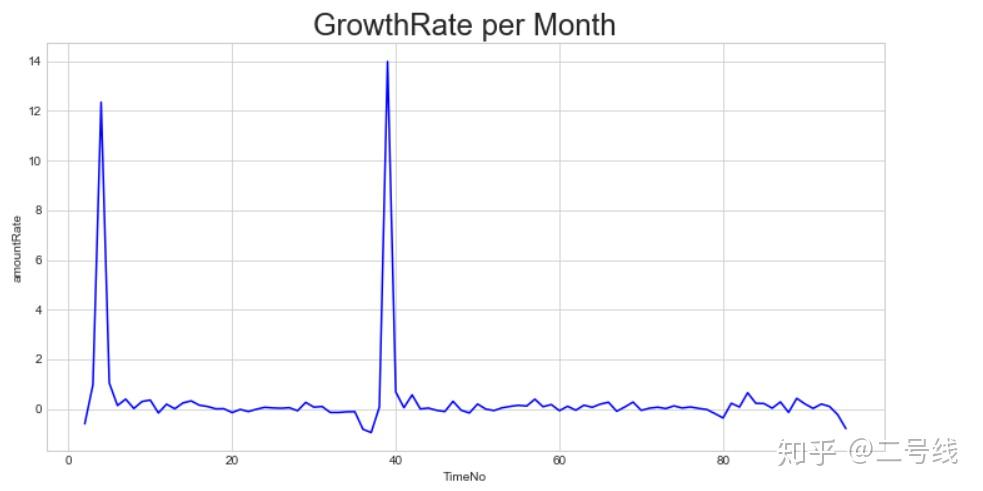 从2005年到2014年期间每个月的增长率,都是比较平稳,没有因为政策或者其他原因导致公司业务量下滑太多,也给投资者以更多信心
从2005年到2014年期间每个月的增长率,都是比较平稳,没有因为政策或者其他原因导致公司业务量下滑太多,也给投资者以更多信心7,最后,展示了一下利率分布的直方图
从平台总体数据来看利率基本维持在0.05~0.35的情况下,这也和美国整体利率较低有关,其中利率最高的0.4975(最高利率)只有2个

整体利率分布:
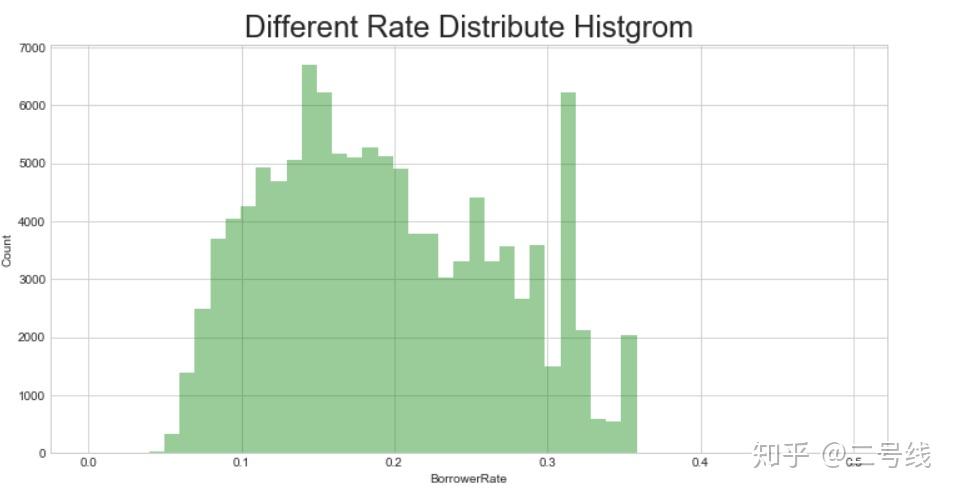 由图可以很清晰的看出利率分布的情况和交易的笔数总计
由图可以很清晰的看出利率分布的情况和交易的笔数总计由以上图形和相关数据,基本可以整个Prosper平台的利率水平和投资者分布情况,以及十年间的总体数据,包括违约率的分布情况等。特别是整体增长率的情况十年间都趋于平稳,也了该平台目前仍处在一个健康的发展状态。
而且,通过2009年前后数据的对比来看,不管是政策上的调整也好,还是模型的重新构建也会,都对平台的违约率有非常明显的效果。
写在最后:由于本人完全小白,对业务数据的分析思路尚且处于萌芽时期,所以不免有些亦步亦趋,对于一些超过Excel处理范畴的大型数据集来说,pandas和R语言是极好的处理工具,由于R语言对统计学的要求较高,所以pandas依然还是初学者的首选。本文只是一个小小的尝试,后续的一些探索式模型分析,比如“某一个州的违约率居高不下”,“收入对违约率的影响”,“信用卡使用程度对违约率的影响”等等,还有待利用RandomForest和逻辑回归的方法建模进行预测等等。
本文大量参考了周荣技:网贷平台Prosper2005~2014数据预测分析一文中的分析思路,且将其中的基本业务分析的文章转换为Python语言来进行处理。也存在很多细节和分析思路上的混乱逻辑,更有代码里的一些不足之处,还望大神们请不吝赐教,为感!!!

2021-02-27

四川发布P2P网贷行业风险提示:没有一家网贷机构业务完全合规
2021-02-19

2021-02-17

2021-02-10

四川发布P2P网贷行业风险提示:没有一家网贷机构业务完全合规_借贷
2021-02-03

2021-01-14

2020-12-28

一刀切,大连要求全市34家P2P网贷机构业务全部出清!_工作领导小组
2020-12-26

2020-12-20

2020-11-28

